Predicting Student Success with Machine Learning: Insights from the Open University Dataset
Machine learning is increasingly being used to support better decision-making in education. In this project, Python-based machine learning models were applied to the Open University dataset to predict student outcomes using demographic and assessment data. The goal was to determine whether data-driven models could identify patterns linked to academic success and help institutions support students more effectively.
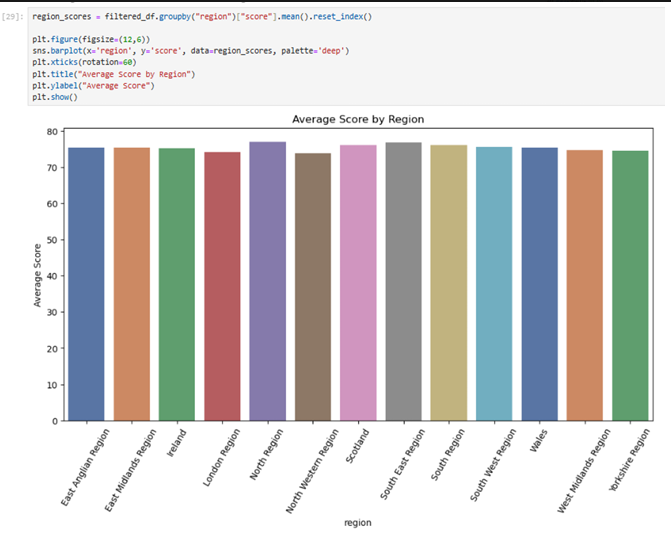
Regional performance across the UK and Ireland showed relatively consistent results, with most average student scores ranging between 74 and 78. Northern England recorded the highest performance, followed closely by the South East and Scotland, while the North West and London regions recorded the lowest average scores. While these differences are relatively small, they provide useful insight into how student outcomes vary geographically. Factors such as demographic composition, educational access, and socioeconomic conditions may influence regional performance trends within the dataset.
Machine Learning Approach
Three classification models were implemented: Logistic Regression, Random Forest, and XGBoost. Logistic Regression provided a baseline model for identifying linear relationships, while Random Forest captured more complex interactions within the data. XGBoost, a boosted ensemble model designed for structured datasets, ultimately delivered the strongest predictive performance. By comparing these models, the project aimed to determine which algorithm was most effective at predicting student outcomes across the dataset.
Data Cleaning and Exploratory Data Analysis
Before training the models, the dataset required several preprocessing steps to ensure accuracy and reliability. Over 9,000 missing values in the imd_band column and more than 4,000 missing values in the date column were removed to improve the quality of the dataset.
Exploratory Data Analysis (EDA) was then conducted using visualisation techniques such as histograms, boxplots, correlation heatmaps, and bar charts. These visualisations helped reveal patterns in student scores, the number of previous attempts, and regional differences in academic performance.
Model Performance Evaluation
The performance of the models was evaluated using classification metrics to determine their predictive accuracy. XGBoost achieved the strongest performance, reaching an accuracy of 63.46%, outperforming Logistic Regression (58.42%) and Random Forest (57.34%).
However, the models struggled to accurately predict underrepresented outcomes such as Distinction and Withdrawn. This limitation highlights the impact of class imbalance, a common challenge in machine learning classification tasks where certain categories appear far less frequently than others.
The results demonstrate the growing potential of machine learning in educational analytics. Predictive models such as those developed in this project could help universities identify students at risk of failing or withdrawing earlier in their academic journey.
By leveraging these insights, institutions could allocate support resources more effectively, implement targeted intervention strategies, and improve overall student retention and success rates.
Future Improvements
While the results are promising, several improvements could enhance the predictive performance of the models. Future work will focus on techniques such as hyperparameter tuning, feature engineering, and improved methods for addressing class imbalance within the dataset.
These refinements could significantly improve classification accuracy and allow machine learning models to provide even more reliable insights into student performance patterns.